



Prelude: Why This Matters
The name FaustARP comes from my least favorite song on Radiohead's In Rainbows. I chose it because it made me realize that even the things we find "ugly" deserve a second look. For a long time, I couldn't understand why that track didn't sit right with me -- until I realized it was the vocals. When I listened to just the instrumental, I found one of the most beautiful arrangements I'd ever heard.
I remember listening to it on a train. When the track ended, I overheard a family nearby. Their youngest daughter said something funny, and only after hearing her parents laugh did she start laughing too. It struck me how naturally she had learned to connect observation with response -- to associate a sound with an emotional state. That small moment made me think about how humans build internal models of the world, connecting what we perceive into something that carries meaning.
That observation became the foundation of my curiosity about how AI systems represent the world. Most AI approaches are very good at pattern matching within a fixed context, but they struggle to carry understanding forward across time. They generate plausible responses without genuinely grounding their knowledge in experience. I became interested in architectures that get closer to forming real cognitive abstractions -- systems that can learn, remember, and reason the way biological minds do.
When I talked about this with my therapist, she pointed out that what drives me isn't a desire to build products, but the need to understand how minds work. FaustARP is my attempt to translate that curiosity into a concrete research program -- one that directly addresses the long-horizon memory limitations I've observed in current AI architectures.
My Work: Long-Term Memory (LTMemory)
The core innovation I've developed over the past year is LTMemory -- a persistent memory mechanism that augments a world model's perception pipeline. The goal is to give the model access to what it has learned across its entire lifetime, not just its recent context window. I began this work on an earlier generative architecture before migrating to a world model foundation that I felt was better suited to the problem of long-horizon reasoning.
The documentation below reflects the baseline LTMemory design and logic. It will be updated as the research progresses through successive versions.
World Model Foundation
Converts observations into a compressed representation of the current moment.
A continuously updated context that accumulates patterns across timesteps -- a running summary of recent experience.
Predicts what comes next without observing it directly -- the model's imagination of future states.
A compressed snapshot of what matters in the current moment. This is where LTMemory integrates.
The complete working representation: the current snapshot combined with accumulated context. Together they answer "what is happening and what led here?"
The prediction engine: given the full state and an action, it forecasts the next observation, expected reward, and whether the episode continues.
The diagram above shows the world model foundation that FaustARP builds on. Before describing the first version, I want to explain how LTMemory slots into this pipeline at a conceptual level.
LTMemory: Conceptual Overview
How the flow works
The system receives an observation (a live frame or a replayed experience) together with prior context.
The observation is encoded into a feature representation -- a structured description of "what is visible right now."
The current perception is used to query the model's long-term memory store. Relevant past knowledge is retrieved as a memory context signal.
A learned arbitration mechanism weighs the current perception against the retrieved memory. Novel inputs are trusted more; familiar inputs defer to memory. This mirrors how biological attention and surprise interact.
The arbitrated signal produces a unified representation that carries both immediate context and long-term knowledge into the downstream model.
Two complementary training objectives keep the memory store accurate and prevent forgetting: one anchors it to current experience, the other consolidates past knowledge through replay.
How LTMemory Works
LTMemory implements a hybrid memory system designed for long-horizon tasks through a dual-process approach that balances immediate perception with accumulated knowledge.
- Efficient Sequential Processing: Observations are handled in structured segments rather than all at once. This keeps computational cost tractable while preserving local coherence across neighboring segments. A working buffer maintains recent context so each segment can attend to what just preceded it.
- Persistent Knowledge Anchors: The model maintains a set of global knowledge representations that persist across its entire training lifetime. These act as stable reference points that help the model recognize recurring patterns even when observations are temporally distant from one another.
- Dynamic Experience Memory: Alongside the persistent anchors, a dynamic memory module continuously updates its knowledge as the model encounters new data. Unlike the static anchors, this component evolves, storing the distributed signal of accumulated experience.
-
Novelty-Based Arbitration: A learned arbitration gate controls how much
weight to give current perception versus retrieved memory:
- Novel input: The gate defers to the current observation, ensuring the model adapts to genuinely new information.
- Familiar input: The gate defers to memory, allowing the model to reconstruct familiar patterns efficiently without redundant computation.
This is analogous to the role of surprise in biological learning -- novel events demand attention; familiar events can be handled by recall. -
Dual-Phase Learning: The memory store is maintained through two internal
objectives:
- Active phase: The memory learns to accurately reconstruct the current stream of incoming observations.
- Consolidation phase: To prevent forgetting, the model periodically replays past experiences, reinforcing older knowledge so new learning does not overwrite it. This is structurally analogous to sleep-based memory consolidation in biological systems.
Chronological Research Log
FaustARPv0 -- Initial Hypothesis: The Perception Bottleneck
What I thought the problem was: I believed the world model's limitations stemmed from its relatively simple perception component. It felt like the model was processing each observation in isolation, without any sense of what it had seen before. My hypothesis was that augmenting the perception pipeline with long-term memory access would substantially improve sample efficiency and long-horizon performance.
In hindsight, I moved too fast and without a deep enough understanding of the full model architecture. I was modifying one component while assuming the effects would flow through to the parts I actually cared about -- something that turned out to be only partially true.
My approach: Integrate LTMemory into the world model's perception encoder.
What I tested: I ran FaustARP V0 against a standard world model baseline on CartPole, expecting clear improvements in both convergence speed and final performance.
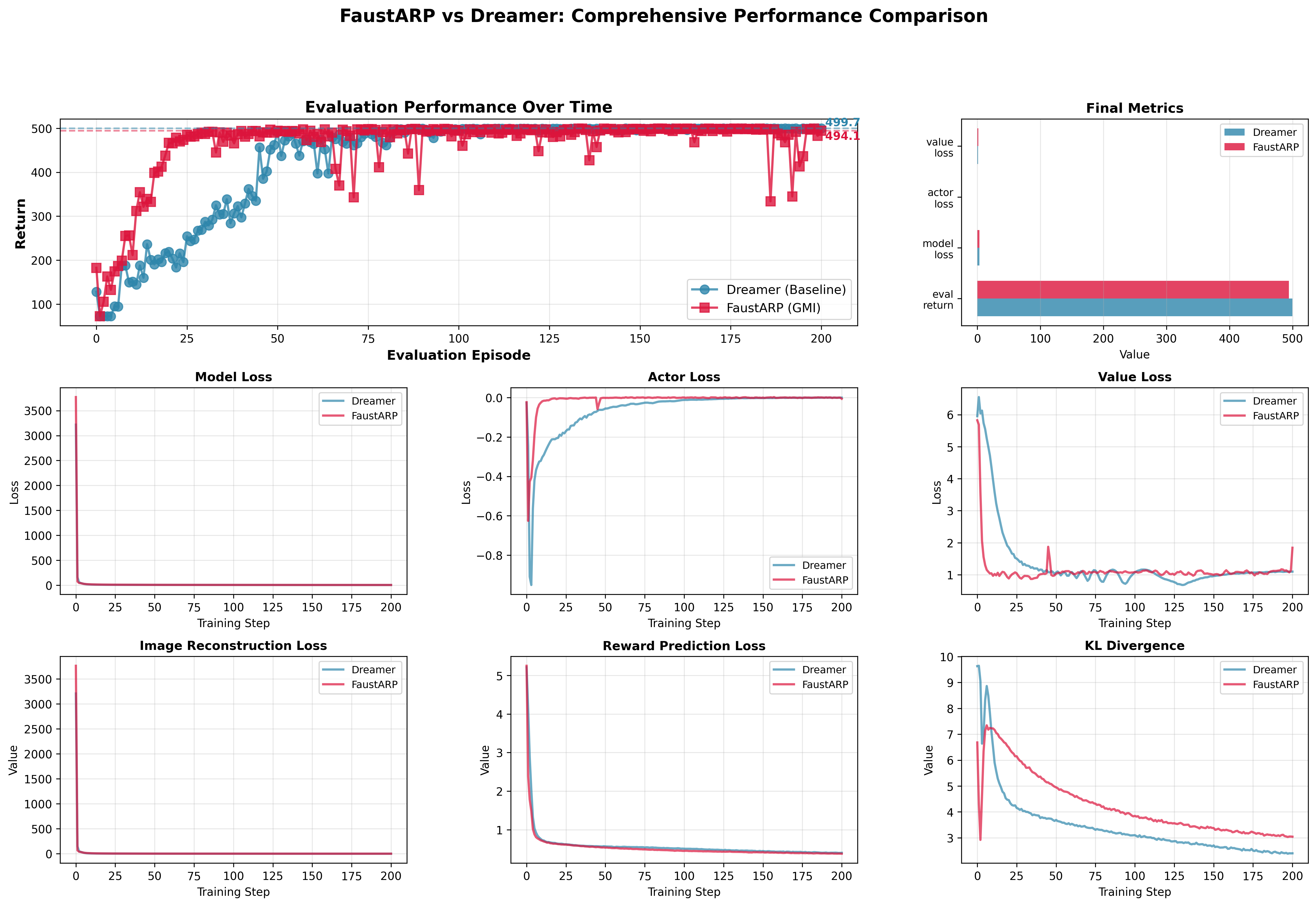
What worked: LTMemory did produce measurable benefits -- faster early convergence and higher final returns. FaustARP V0 reached stronger performance with fewer environment steps.
What I missed: The improvements were more modest than predicted. More importantly, I realized I didn't fully understand why the changes were helping -- which made it difficult to know where to go next.
Key insight: Studying the architecture more carefully, I discovered that the encoder primarily influences the learning signal during training rather than the model's imagination capability. This meant that augmenting the "eye" wasn't directly improving the "mind's" ability to reason about the future.
What I learned: The encoder modification acts as a learning accelerator by providing cleaner training targets, but it doesn't reshape how the model builds and uses its internal world representation. The deeper bottleneck was elsewhere.
Retrospective note: The benchmark task was too simple to stress-test the memory system properly. Early results looked modest because we had actually hit the performance ceiling of the environment -- not because the changes weren't working.
I was also carrying a confound from a pre-trained feature extractor in early runs, which partly explained the faster initial gains. Removing it gave a cleaner picture of what LTMemory was actually contributing.
v0.5 -- Revised Hypothesis: The Reasoning Bottleneck
How V0 changed my thinking: Once I controlled for the confound and ran clean benchmarks, I understood the architecture more clearly. The encoder improvement helps during training, but the model's core long-horizon reasoning -- how it builds and maintains context over time -- lives deeper in the architecture. That became my new focus.
Before changing anything, I ran fresh benchmarks to establish a clean baseline and confirmed that LTMemory still produced consistent improvements even without the confound:
In the CartPole evaluation videos, FaustARP V0 visibly holds the pole stable for the first 80 steps despite being only around 25 episodes into training. This early behavioral stability is not observed in the baseline. (4th video below)
Why this matters
In the first 80 steps of this run, FaustARP V0 consistently stabilizes the task despite being only ~25 episodes into training. This early stability is not seen in the baseline and demonstrates faster convergence and more robust early-phase control.
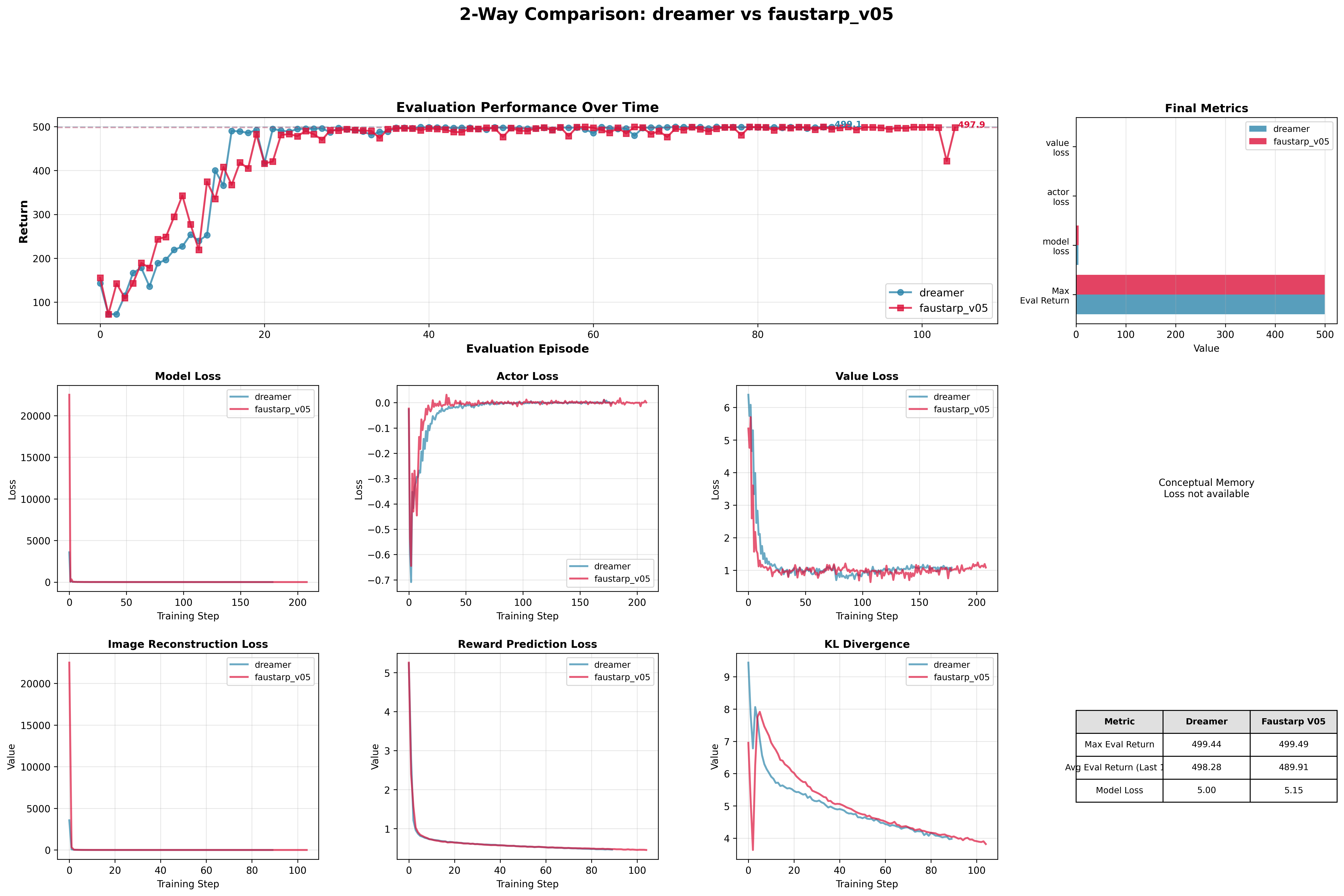
Without the pre-trained extractor, V0.5 performance on CartPole aligns more closely with the baseline. This was expected -- and useful -- because it confirmed that CartPole is too simple to reveal the benefits of a long-term memory system. I moved to a more demanding continuous control task where temporal context actually matters.
New experiment: I ran FaustARP V0.5 against the baseline on a continuous locomotion task (Walker2D), comparing behavior across multiple evaluation episodes.
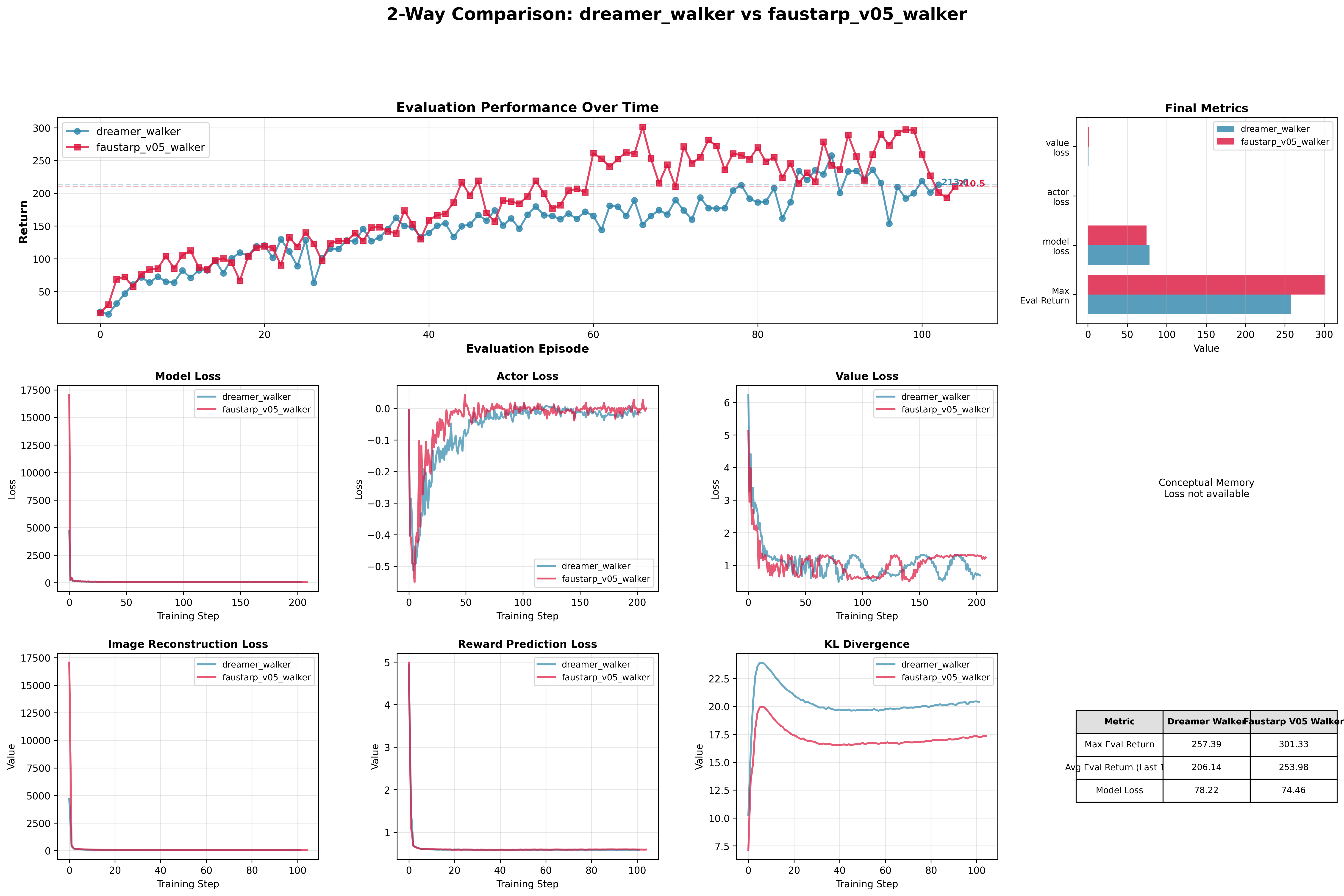
Key outcome: The locomotion experiments confirmed the revised hypothesis. FaustARP V0.5 achieved the training efficiency improvements I originally expected from V0, on a task where long-horizon context is actually load-bearing.
I then introduced a deliberate stress test: both models were reset after 100k steps of training to evaluate resilience and recovery.
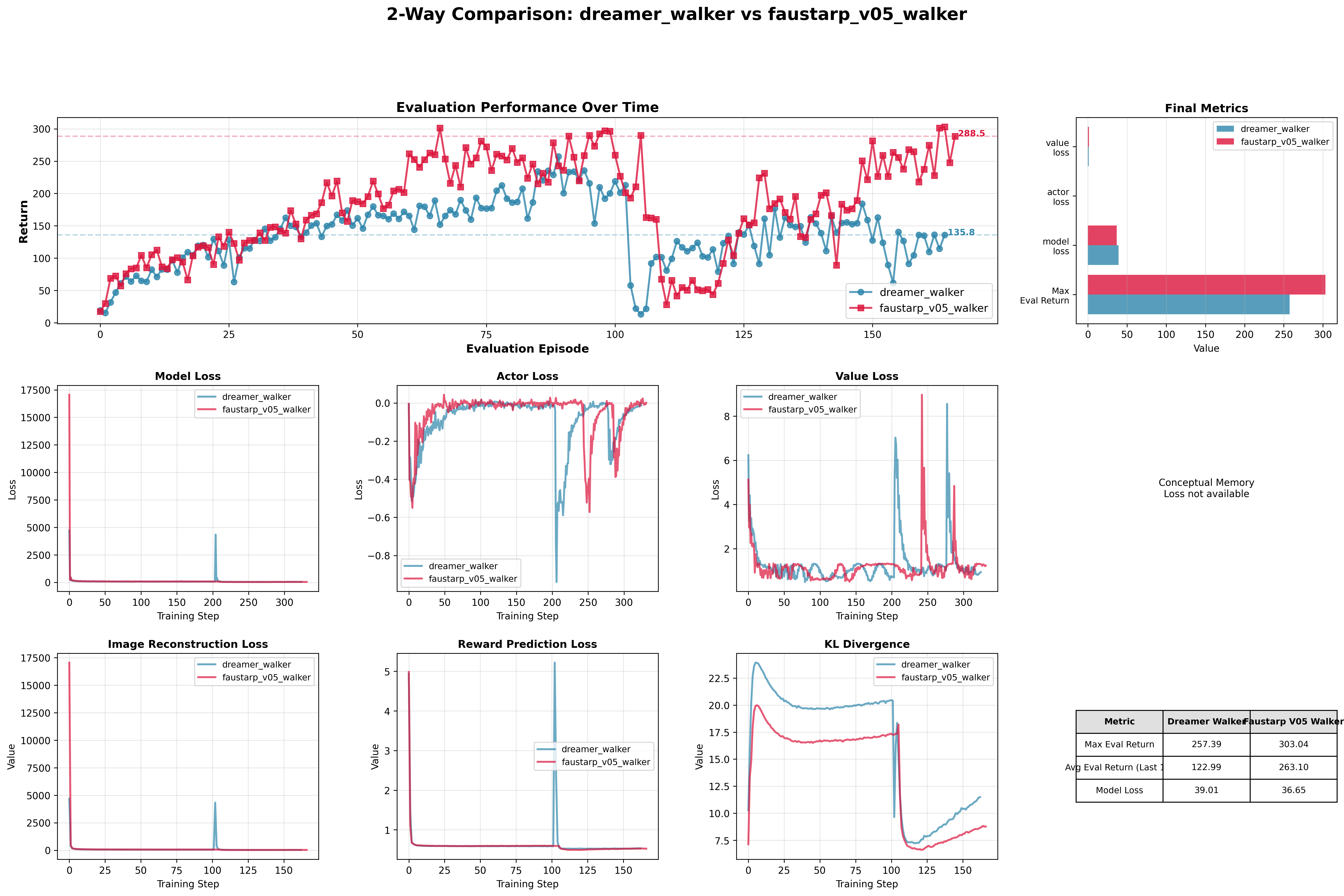
The baseline failed to recover from the reset and performance degraded significantly -- likely because it had no mechanism to anchor its representation to what it had learned before the disruption. FaustARP recovered quickly and returned to its prior performance trajectory, which suggests the long-term memory component provides genuine resilience, not just faster early-stage learning.
Key Results and Lessons Learned
Main finding: LTMemory works -- and the reason matters.
My initial hypothesis was partially right: augmenting the perception component did improve performance. But the mechanism was different from what I expected. Understanding why it works -- rather than just that it does -- changed the direction of the research.
What I Got Wrong
- Architectural assumptions: I initially overestimated how directly perception improvements would translate to better imagination and planning. The training and inference pathways in a world model are more distinct than I realized.
- Benchmark selection: Simple control tasks hit their performance ceiling quickly. Demonstrating the value of long-term memory requires tasks where temporal context is genuinely necessary for success.
Direction Forward
With LTMemory validated at the encoder level, the natural next step is to understand how it behaves when placed deeper in the architecture -- closer to where the model's reasoning and planning actually happen. There are also open questions about the best way to combine multiple memory processes within a single system, and how to build the tooling needed to monitor and interpret model behavior at scale.
Longer term, making the model's internal reasoning legible -- not just to researchers but potentially to the users of systems built on it -- is a direction I find compelling both technically and philosophically.
Open question: How do biological systems maintain coherent representations over very long timescales? Is there a structural principle being used that AI architectures haven't yet captured, or is it largely a question of scale and the right training objectives?
V1: A Second Look
V1 represents a significant step forward from the work above. It is a tested, working implementation that brings the LTMemory concept into a transformer-based architecture, extending the approach beyond the original world model foundation.
In the coming months, the focus will shift to rigorous benchmarking of the expanded system and exploring how the memory components interact across different positions in the architecture.
If you've read this far, thank you. I hope this gives a clear enough picture of the work and the thinking behind it. I wish you the very best.