



Prelude: Why This Matters
The name FaustARP comes from my least favorite song on Radiohead's In Rainbows. I chose it because It's made me realized that even the things we find "ugly" deserve a second look. For a long time, I couldn't understand why that song didn't sit right with me, until I realized it was the vocals. When I focused just on the instrumental, I discovered one of the most beautiful arrangements I've ever heard.
I remember listening to it on a train. When the track ended, I overheard a family nearby. Their youngest daughter said something funny, and only after hearing her parents laugh did she start laughing too. It struck me how naturally she had learned to connect observation with emotion, to associate the sound of laughter with joy. That small moment made me think about how humans build internal models of the world, connecting what we see and feel into meaning.
That thought became the foundation of my curiosity about world models in AI. While previous to that change of perspective, I was stuck on Variational Autoencoders (VAEs). VAEs can simulate basic perception better than causal LLMs which can generate associations but neither truly *understand* the world they describe. World models, however, get closer to forming real cognitive abstractions.
When I talked about this with my therapist, she pointed out that what drives me isn't a desire to build products but the need to understand consciousness itself.
FaustARP represents my attempt to translate my cognitive insights over the course of this project into a concrete architectural framework. It is one that addresses the fundamental limitations I've observed in current world model approaches.
My Work: Long-Term Memory (LTMemory)
The key innovation I worked on for the past year is LTMemory (Long-Term Memory), a persistent memory mechanism integrated into both the encoder reaching back to the attention class itself. I oringinally built it on a VAE architecture to help it learn faster in order to keep up with big labs but as i learned about world models i completely shifted from VAEs to the DreamerV3 architecture.
The entire Documentation will be based on the following baseline LTMemory explanation and logic but may be updated in incremental versions.
DreamerV3 Architecture Overview
Converts image frames into a compressed understanding of what's happening right now
A continuously-updated scratchpad that remembers patterns across multiple timesteps like a running summary of recent events.
Guesses what's happening next without looking at the current observation like predicting the next video frame before seeing it.
A compressed snapshot of "what matters" in the current moment. This is where LTMemory integrates.
The complete working memory: the snapshot (Discrete Embedding) + the context (Recurrent State). Together, they answer "what's happening and what led to it?"
The predictor engine: given the full state + action, it forecasts the next observation, reward, and whether the episode continues.
What you just saw is the standard DreamerV3 architecture. Before I start with the first version of FaustARP I want to explain the LTMemoryEncoder architecture.
LTMemoryEncoder Architecture Overview
Diagram Flow Walkthrough
Begin at the top-left. The system takes an Image Frame (either a live observation or sampled from the Replay Buffer) along with the previous state context.
Follow the arrow to the CNN Backbone. This converts the raw image into Flattened Features - representing "what is seen right now."
The features act as a Query to search the global PM Slots. Note how the arrows flow into Similarity Score → Attention Weights → Memory Context. This is the model "remembering."
Both the Input (Flattened) and Memory (Context) feed into the orange Gating Sigmoid. This node decides: is this new (trust input) or familiar (trust memory)?
The gate's decision creates a Fused Representation. This output flows down to generate the Posterior (for learning) and Prior (for dreaming).
Finally, look at the dashed lines at the bottom. Waking Loss checks if we can reconstruct the image. Dreaming Loss ensures the Prior's imagination matches reality.
(Persistent Memory)"] FLAT --> Q_PROJ[Query Projection] PM --> K_PROJ[Key Projection] PM --> V_PROJ[Value Projection] Q_PROJ --> ATTN_S[Similarity Score] K_PROJ --> ATTN_S ATTN_S --> ATTN_W[Attention Weights] ATTN_W --> CTX[Memory Context] V_PROJ --> CTX FLAT --> GATE_IN[Input Feature] CTX --> GATE_MEM[Memory Feature] GATE_IN --> SIGMOID{"Gating Sigmoid
(Surprise-Based)"} GATE_MEM --> SIGMOID SIGMOID --> FUSED[Fused Representation] end FUSED --> OUT_PROJ[Output Projection] end subgraph "Training & Loss" OUT_PROJ --> POST["Posterior q(z_t|...)"] OUT_PROJ --> PRIOR["Prior p(z_t|...)"] POST --> Z_LATENT["z_t Discrete"] Z_LATENT --> RECON[Reconstruction] RECON -.->|Waking Loss| IMG PRIOR -.->|Dreaming Loss| Z_LATENT end subgraph "Chunking & Replay" REPLAY[Replay Buffer] -->|Sample Sequence| IMG CHUNK["Chunked Attention
(Backprop through Time)"] -.-> PM end style IMG fill:#5e7ce2,stroke:#fff,stroke-width:2px,color:#fff style SIGMOID fill:#ff9f43,stroke:#fff,stroke-width:2px,color:#fff style Z_LATENT fill:#5e7ce2,stroke:#fff,stroke-width:2px,color:#fff
How LTMemory Works
The LTMemory architecture implements a hybrid memory system designed to handle infinite context lengths through a "Dual-process" approach that balances immediate perception with long-term consolidation.
-
Sequential Chunking & Tiling: The input (e.g., a high-resolution image) is
processed in sequential chunks (tiles). This reduces the computational complexity from quadratic
O(N^2)to linear-block complexity. A Chunk Memory buffer retains the hidden states of recent chunks, allowing for local cross-attention (Working Memory) between neighbors. - Persistent Memory (PM) Slots: Every chunk attends to a set of globally shared PM Slots. These are learnable, static parameters (similar to "soft prompts") that persist across the entire lifetime of the model. They provide a stable, global context anchor that helps the model recognize universal features across disjoint chunks.
- Neural Memory (NM): Parallel to the attention stream, the input queries a secondary Neural Memory module, an MLP-based Key-Value store acting as a "generative memory." Unlike the static PM slots, this memory is dynamic and stores distributed representations of data it has seen.
-
Surprise-Based Gating: A learnable Sigmoid gate acts as a "Confidence Switch"
effectively modelling surprise:
- High Surprise (Novelty): The gate opens to the Input stream (Attention output), forcing the model to learn from the new, unexpected data.
- Low Surprise (Familiarity): The gate relies on Memory retrieval, utilizing the compressed knowledge in the Neural Memory to reconstruct the signal efficiently.
Z_fused = (1 - λ)+ Input + λ+ Memory(where λ ≈ 1 indicates high familiarity/low surprise) -
Sleep-Wake Learning: The Neural Memory is maintained via two specialized internal
objectives, distinct from the global VAE loss:
- Waking Loss (Encoding): The memory trains to reconstruct the current active stream of data, minimizing the reconstruction error of the immediate inputs.
- Dreaming Loss (Consolidation): To prevent catastrophic forgetting, the model samples past states from a Replay Buffer. The memory is trained to reconstruct these "dreamt" samples, ensuring that new learning does not overwrite established long-term knowledge.
Chronological Research Log
FaustARPv0 - Initial Hypothesis: The Perceptual Bottleneck
What I thought the problem was: I was convinced that DreamerV3's limitations came from its simple CNN architecture. The standard encoder felt like it missed out on a lot of potential. Moreover did i think that the dreamer was lacking at memory of previous frames and naturally involving that context when looking at current observations.
My main problem was that I rushed this project whole excitedly and without much understanding of the complex Dreamer architecture, thinking I was modifying the World Model directly, I was working on the Standardization encoder which is the helper of the posterior net which plays into the discrete embedding.
My approach: Replace the standard DreamerEncoder with the LTMemory Encoder.
What I tried: I ran FaustARP V0 against vanilla DreamerV3 on CartPole, expecting dramatic improvements in sample efficiency and long-horizon reasoning.
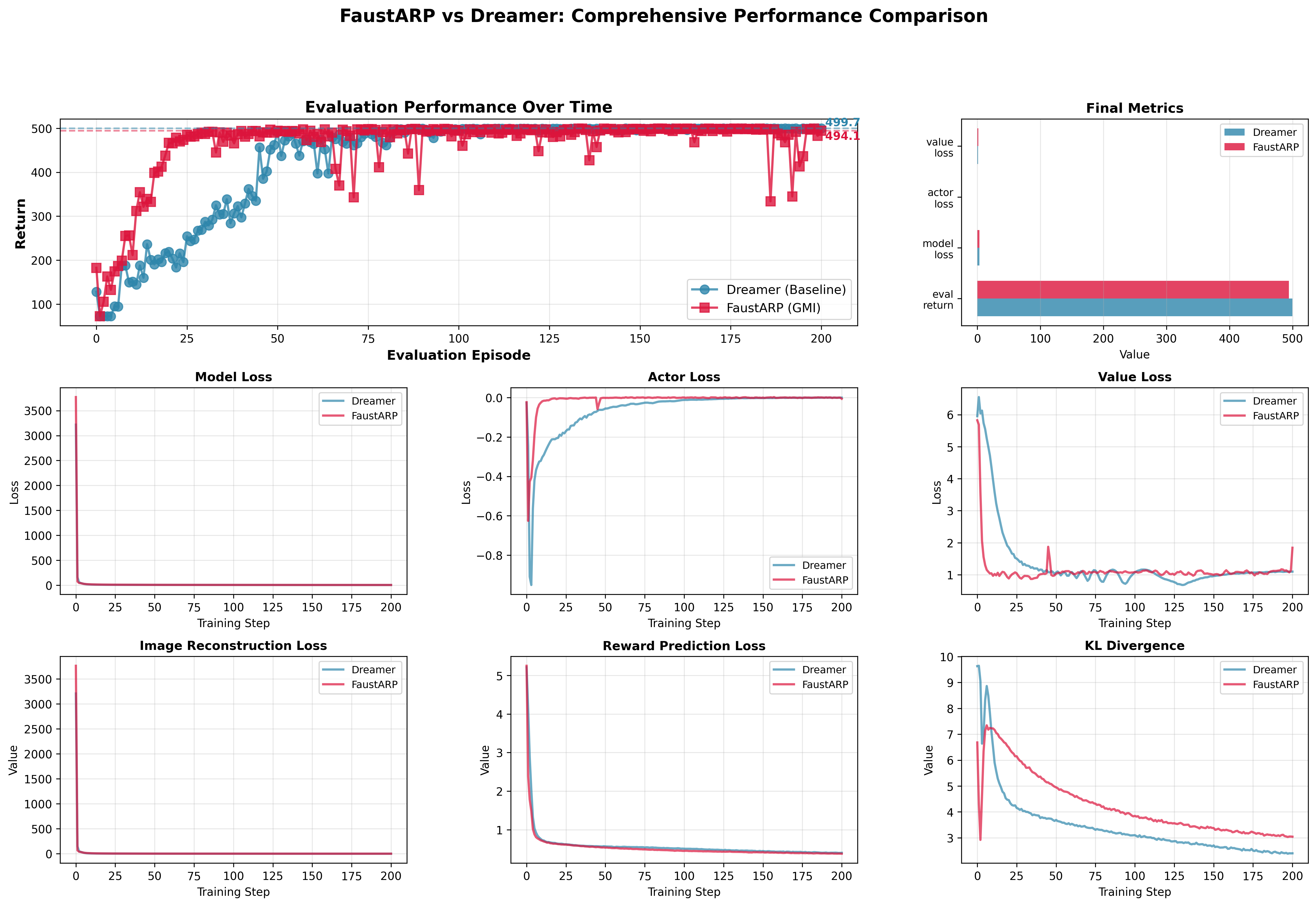
What worked: The LTMemoryEncoder did provide benefits--faster convergence and higher final performance. FaustARP V0 reached better rewards with fewer environment steps.
What failed: The improvements were more modest than I predicted. More importantly, I realized I didn't fully understand why the encoder was helping.
Key insight: Looking at the RSSM architecture more carefully, I discovered that the encoder only feeds the posterior path during training, not the prior path used for imagination. This meant my "better eye" wasn't directly improving the "brain's" reasoning capabilities.
What I learned: The encoder acts as a "convergence accelerator" by providing cleaner training targets, but it doesn't change the fundamental architecture of the imagination engine. The real bottleneck might be elsewhere.
Note from the future: The task was way too simple to benchmark both models properly. I initially thought the convergence of eval returns meant my changes weren't significant enough, but I later realized we had simply hit the maximum reward ceiling for the environment.
Another realization: I was using a pretrained SWIN model, which likely contributed to the faster initial performance improvements I observed.
v0.5 - Revised Hypothesis: The Conceptual Coherence Bottleneck
How v0 changed my view: The later realization that I was using a SWIN pretrained model made me fallback to a new feature extractor training from scratch which sped up the architecture drastically. After learning more about the Dreamer architecture I realized that the encoder only helps during training (not inference), and the core limitation must be in the dynamics model itself, specifically how it maintains and reasons about long-term context.
But before changing anything I ran new benchmarks without the SWIN Extractor and still had promising results:
In the CartPole evaluation videos, you can see FaustARP V0 holding the pole upright for the first 80 steps, even though it's only ~25 episodes into training. This early stability isn't observed in the DreamerV3 baseline. (4th Video)
Why this matters
In the first 80 steps of this run, FaustARP V0 consistently holds the pole upright, despite being only ~25 episodes into training. This early stability is not observed in the DreamerV3 baseline and highlights FaustARP's faster convergence and more resilient short-horizon control.
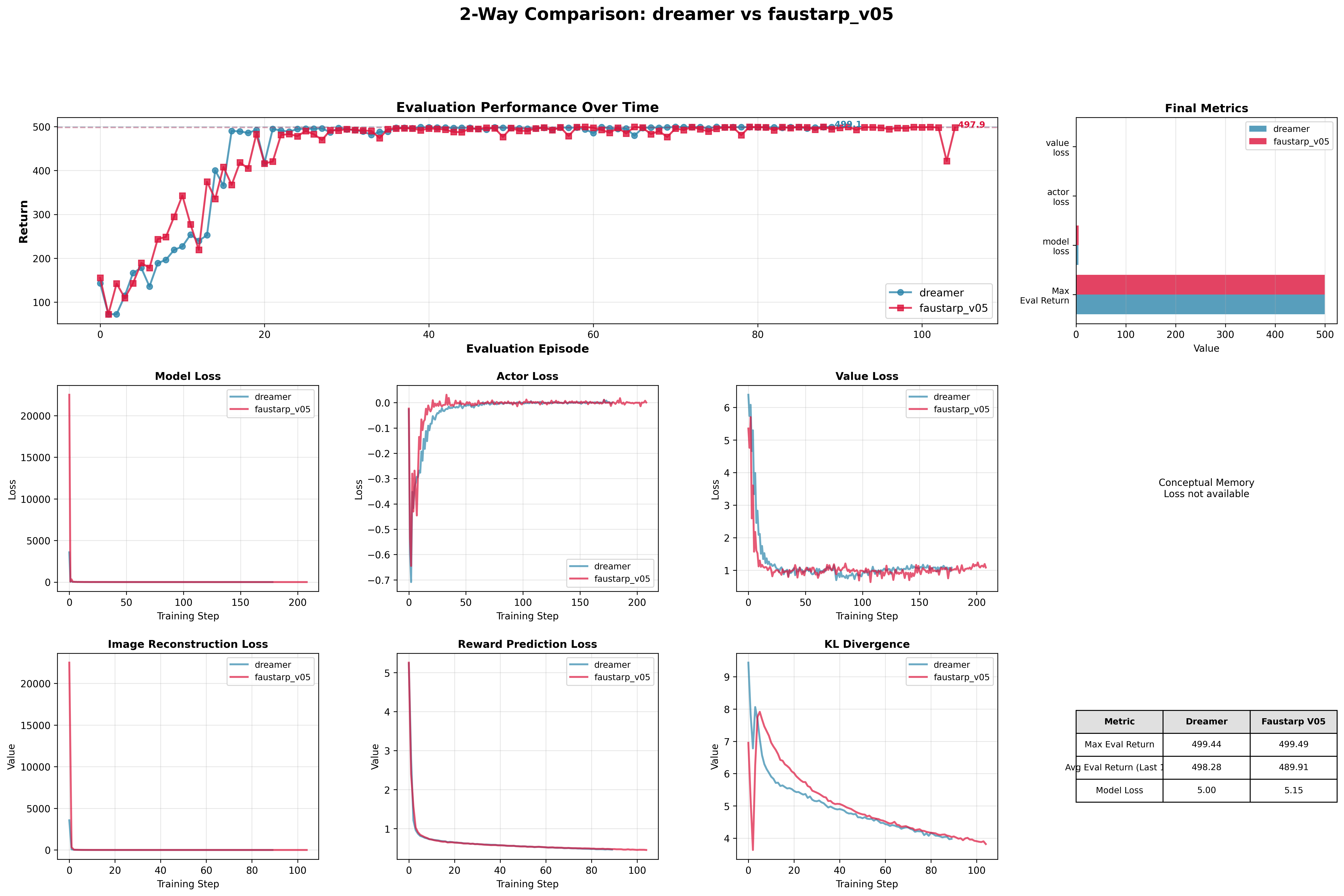
This plot shows the new V05 without the SWIN pretrained which seems to perform no better than DreamerV3. From the first V0 test though, i had learned that the cartpole was insufficient for testing long term memory and i moved on to a more difficult task, the dmc walker:
The new experiment: I ran additional experiments on Walker2D to test this revised hypothesis, comparing FaustARP V0.5 against DreamerV3 across multiple episodes.
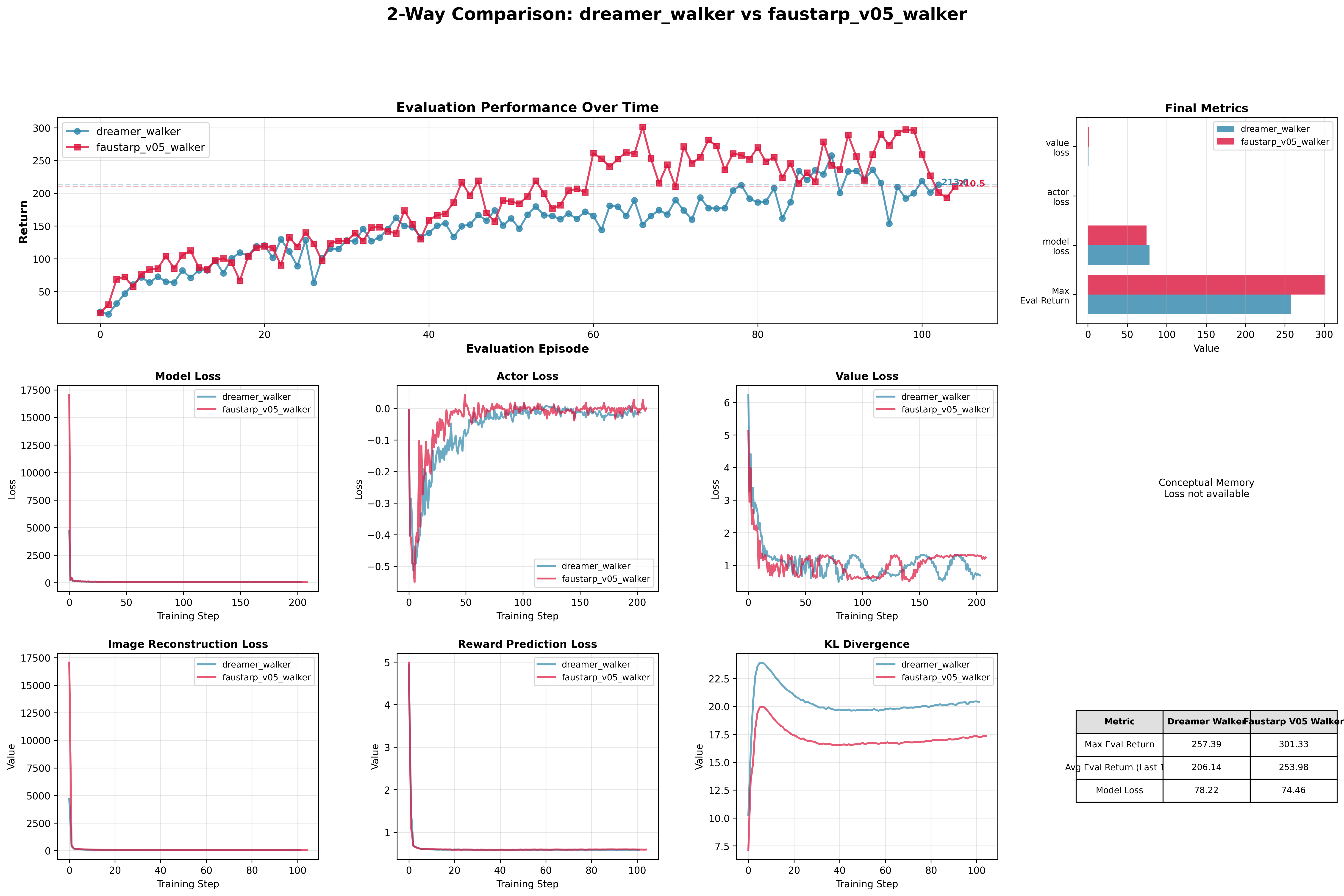
Key outcome: The Walker experiments confirmed my revised hypothesis. FaustARP V05 now achieves what I originally expected from V0, it showed improvements in training efficiency. I even went further and reset both datasets after 100k steps and continued training to see how the models behave, as you can see in the following plot
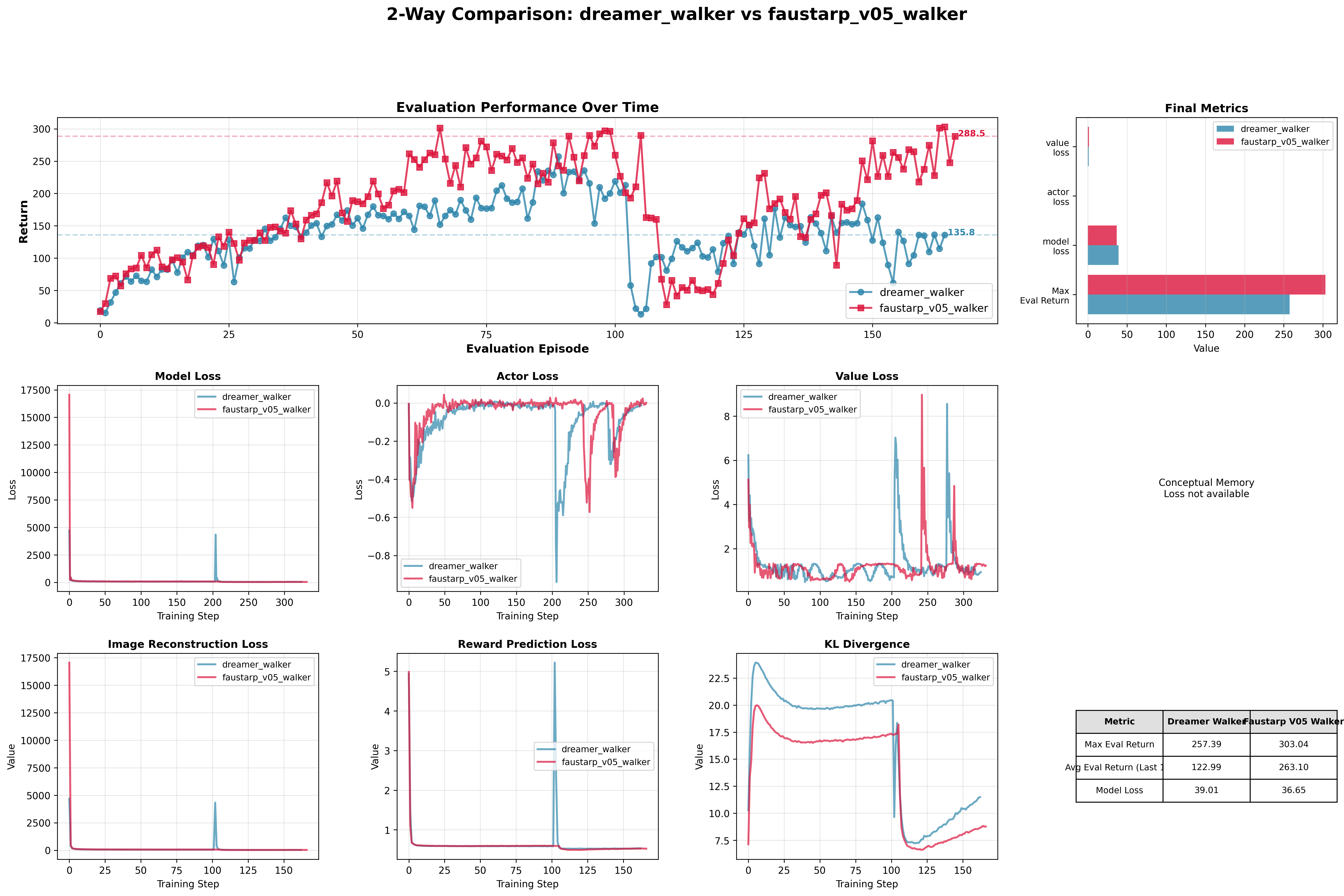
the dreamer failed to recover from the reset and started to perform poorly, probably due to learning wrong signals and rewards while the faustarp recovered fast and managed to get back on track.
Key Results and Lessons Learned
Main Finding: LTMemory WORKS!
My initial hypothesis was partially correct--the ImageGMIEncoder did improve performance--but I was wrong about why.
What I Got Wrong
- Architectural Understanding: I didn't fully grasp how the RSSM's posterior vs. prior pathways work. The encoder only helps during training, not during imagination/planning.
- Scope of Improvements: The benefits were more modest than I predicted and concentrated in early-to-mid training stages.
Next Steps / Open Questions
Where I'd go next: Since weve established the LTMemory I want to experiment with it in different parts of the architceture, inside the world model only or with the standard encoder ltmemory making it a dual system. i want to get the most potential out of my LTMemory. Another thing i want to work on is a framework for me to be able to monitor my models training or an engine for it to learn in while this is a much more time consuming process. One architectural addition i want to make after im satisfied with my LTMemory is to add a text based world model and make FaustARP mixture of experts to be able to explain its thinking process to the user. Of course these are very ambitious goals and i expect to face a lot of challenges and setbacks but i think its important to have a clear path forward and a roadmap to follow.
What still confuses me: How do biological systems maintain coherent internal representations over long periods? Is there a fundamental architectural principle I'm missing, or is it just a matter of scale and complexity?
V1 Experiment: A Second Look
This is a big jump forward and where I am right now.
The V1 is a tested and working transformer version of the previous FaustARP architecture.
In the following weeks and months i will be benchmarking the first thing i set out to do above, trying a dual based FaustARP with multiple LTMemories, one where we validated and one in the World Model
I am currently experiencing a massive burnout and on a break from my projects while i apply for universities and work on this Journal, if youve read this far, I want to thank you for your time and hope i have made this clear enough for you to understand. I wish you the very best in life